This paper introduces the UCFE: User-Centric Financial Expertise benchmark, an innovative framework designed to evaluate the ability of large language models (LLMs) to handle complex real-world financial tasks. UCFE benchmark adopts a hybrid approach that combines human expert evaluations with dynamic, taskspecific interactions to simulate the complexities of evolving financial scenarios. Firstly, we conducted a user study involving 804 participants, collecting their feedback on financial tasks. Secondly, based on this feedback, we created our dataset that encompasses a wide range of user intents and interactions. This dataset serves as the foundation for benchmarking 12 LLM services using the LLM-as-Judge methodology. Our results show a significant alignment between benchmark scores and human preferences, with a Pearson correlation coefficient of 0.78, confirming the effectiveness of the UCFE dataset and our evaluation approach. UCFE benchmark not only reveals the potential of LLMs in the financial sector but also provides a robust framework for assessing their performance and user satisfaction.The benchmark dataset and evaluation code are available.
@article{yang2024ucfeusercentricfinancialexpertise,title={UCFE: A User-Centric Financial Expertise Benchmark for Large Language Models},author={Yang*, Yuzhe and Zhang*, Yifei and Hu, Yan and Guo, Yilin and Gan, Ruoli and He, Yueru and Lei, Mingcong and Zhang, Xiao and Wang, Haining and Xie, Qianqian and Huang, Jimin and Yu, Honghai and Wang, Benyou},year={2024},journal={arXiv preprint},archiveprefix={arXiv},primaryclass={q-fin.CP},url={https://arxiv.org/abs/2410.14059},note={A User-Centric framework designed to evaluate LLMs' ability to handle complex financial tasks},}
FAST-CA: Fusion-based Adaptive Spatial-Temporal Learning with Coupled Attention for airport network delay propagation prediction
Chi Li , Xixian Qi , Yuzhe Yang , Zhuo Zeng , Lianmin Zhang , and Jianfeng Mao
Information Fusion, 2024
SOTA spatio-temporal model for predicting airport network delay propagation
The issue of delay propagation prediction in airport networks has garnered increasing global attention, particularly due to its profound impact on operational efficiency and passenger satisfaction in modern air transportation systems. Despite research advancements in this domain, existing methodologies often fall short of comprehensively addressing the challenges associated with predicting delay propagation in airport networks, especially in terms of handling complex spatial-temporal dependencies and sequence couplings. In response to the complex challenge of predicting delay propagation in airport networks, we introduce the Fusion-based Adaptive Spatial-Temporal Learning with Coupled Attention (FAST-CA) framework. FAST-CA is an innovative model that integrates dynamic and adaptive graph learning, coupled attention mechanisms, periodicity feature extraction, and multifaceted information fusion modules. This holistic approach enables a thorough analysis of the interplay between flight departure and arrival delays and the spatial-temporal correlations within airport networks. Rigorously evaluated on two extensive real-world datasets, our model consistently outperforms current state-of-the-art baseline models, showcasing superior predictive performance and the effective learning capabilities of its intricately designed modules. Our research highlights the criticality of analyzing spatial-temporal relationships and the dynamics of flight coupling, offering significant theoretical and practical contributions to the advancement and management of air transportation systems.
@article{LI2024102326,title={FAST-CA: Fusion-based Adaptive Spatial-Temporal Learning with Coupled Attention for airport network delay propagation prediction},journal={Information Fusion},pages={102326},year={2024},issn={1566-2535},doi={https://doi.org/10.1016/j.inffus.2024.102326},url={https://www.sciencedirect.com/science/article/pii/S1566253524001040},author={Li, Chi and Qi, Xixian and Yang, Yuzhe and Zeng, Zhuo and Zhang, Lianmin and Mao, Jianfeng},keywords={Graph neural networks, Flight delay prediction, Delay propagation, Dynamic graph, Adaptive learning},note={SOTA spatio-temporal model for predicting airport network delay propagation}}
Open-FinLLMs: Open Multimodal Large Language Models for Financial Applications
Qianqian Xie , Dong Li , Mengxi Xiao , Zihao Jiang , Ruoyu Xiang , Xiao Zhang , Zhengyu Chen , Yueru He , Weiguang Han , Yuzhe Yang , and 29 more authors
arXiv preprint, 2024
First open-source financial multimodal LLM: FinLLaVA-8B
Large language models (LLMs) have advanced financial applications, yet they often lack sufficient financial knowledge and struggle with tasks involving multi-modal inputs like tables and time series data. To address these limitations, we introduce Open-FinLLMs, a series of Financial LLMs. We begin with FinLLaMA, pre-trained on a 52 billion token financial corpus, incorporating text, tables, and time-series data to embed comprehensive financial knowledge. FinLLaMA is then instruction fine-tuned with 573K financial instructions, resulting in FinLLaMA-instruct, which enhances task performance. Finally, we present FinLLaVA, a multimodal LLM trained with 1.43M image-text instructions to handle complex financial data types. Extensive evaluations demonstrate FinLLaMA’s superior performance over LLaMA3-8B, LLaMA3.1-8B, and BloombergGPT in both zero-shot and few-shot settings across 19 and 4 datasets, respectively. FinLLaMA-instruct outperforms GPT-4 and other Financial LLMs on 15 datasets. FinLLaVA excels in understanding tables and charts across 4 multimodal tasks. Additionally, FinLLaMA achieves impressive Sharpe Ratios in trading simulations, highlighting its robust financial application capabilities. We will continually maintain and improve our models and benchmarks to support ongoing innovation in academia and industry.
@article{xie2024openfinllmsopenmultimodallarge,title={Open-FinLLMs: Open Multimodal Large Language Models for Financial Applications},journal={arXiv preprint},year={2024},author={Xie, Qianqian and Li, Dong and Xiao, Mengxi and Jiang, Zihao and Xiang, Ruoyu and Zhang, Xiao and Chen, Zhengyu and He, Yueru and Han, Weiguang and Yang, Yuzhe and Chen, Shunian and Zhang, Yifei and Shen, Lihang and Kim, Daniel and Liu, Zhiwei and Luo, Zheheng and Yu, Yangyang and Cao, Yupeng and Deng, Zhiyang and Yao, Zhiyuan and Li, Haohang and Feng, Duanyu and Dai, Yongfu and Somasundaram, VijayaSai and Lu, Peng and Zhao, Yilun and Long, Yitao and Xiong, Guojun and Smith, Kaleb and Yu, Honghai and Lai, Yanzhao and Peng, Min and Nie, Jianyun and Suchow, Jordan W. and Liu, Xiao-Yang and Wang, Benyou and Lopez-Lira, Alejandro and Huang, Jimin and Ananiadou, Sophia},note={First open-source financial multimodal LLM: FinLLaVA-8B},}
FedDTPT: Federated Discrete and Transferable Prompt Tuning for Black-Box Large Language Models
Jiaqi Wu , Simin Chen , Yuzhe Yang , Yijiang Li , Shiyue Hou , Rui Jing , Zehua Wang , Wei Chen , and Zijian Tian
arXiv preprint, 2024
A federated prompt tuning method for black-box LLMs, enhancing privacy, efficiency, and performance on non-iid data
In recent years, large language models (LLMs) have significantly advanced the field of natural language processing (NLP). By fine-tuning LLMs with data from specific scenarios, these foundation models can better adapt to various downstream tasks. However, the fine-tuning process poses privacy leakage risks, particularly in centralized data processing scenarios. To address user privacy concerns, federated learning (FL) has been introduced to mitigate the risks associated with centralized data collection from multiple sources. Nevertheless, the privacy of LLMs themselves is equally critical, as potential malicious attacks challenge their security, an issue that has received limited attention in current research. Consequently, establishing a trusted multi-party model fine-tuning environment is essential. Additionally, the local deployment of large LLMs incurs significant storage costs and high computational demands. To address these challenges, we propose for the first time a federated discrete and transferable prompt tuning, namely FedDTPT, for black-box large language models. In the client optimization phase, we adopt a token-level discrete prompt optimization method that leverages a feedback loop based on prediction accuracy to drive gradient-free prompt optimization through the MLM API. For server optimization, we employ an attention mechanism based on semantic similarity to filter all local prompt tokens, along with an embedding distance elbow detection and DBSCAN clustering strategy to enhance the filtering process. Experimental results demonstrate that, compared to state-of-the-art methods, our approach achieves higher accuracy, reduced communication overhead, and robustness to non-iid data in a black-box setting. Moreover, the optimized prompts are transferable.
@article{wu2024feddtptfederateddiscretetransferable,title={FedDTPT: Federated Discrete and Transferable Prompt Tuning for Black-Box Large Language Models},author={Wu, Jiaqi and Chen, Simin and Yang, Yuzhe and Li, Yijiang and Hou, Shiyue and Jing, Rui and Wang, Zehua and Chen, Wei and Tian, Zijian},year={2024},journal={arXiv preprint},url={https://arxiv.org/abs/2411.00985},note={A federated prompt tuning method for black-box LLMs, enhancing privacy, efficiency, and performance on non-iid data}}
FDPT: Federated Discrete Prompt Tuning for Black-Box Visual-Language Models
Jiaqi Wu , Simin Chen , Jing Tang , Yuzhe Yang , Lixu Wang , Song Lin , Zehua Wang , Wei Chen , and Zijian Tian
2024
A federated discrete prompt tuning method for black-box VLMs, improving accuracy and efficiency while protecting privacy
General-purpose Vision-Language Models (VLMs) have driven major advancements in multimodal AI. Fine-tuning these models with task-specific data enhances adaptability to various downstream tasks but suffers from privacy risks. While potential solutions like federated learning can address user data privacy concerns, model protection is also essential. Other methods that rely on black-box VLM APIs usually require the access of prediction logits, leaving them open to inversion attacks. Moreover, addressing the challenges of tuning complexity and data transmission efficiency in federated VLM scenarios is also crucial. To address these challenges, we propose FDPT—a federated discrete prompt tuning method utilizing black-box VLM APIs. The black-box VLM is restricted to output text only, without relying on traditional prediction logits. In the client optimization stage, we design an AI agent-driven, token-level prompt optimization method that employs a Generate-Feedback mechanism to iteratively learn task experience. Additionally, we use an Exploration-Exploitation Balance strategy to drive a Progressive Prompt Refinement Chain-of-Thought, adaptively controlling the optimization scale. In the global aggregation stage, we propose a Semantic-similarity-guided Evolutionary Computation method, filtering local discrete tokens based on semantic similarity to enable unsupervised selection of representative tokens. Experimental results show that, compared to eight state-of-the-art methods, FDPT significantly improves accuracy in traditional image classification and visual question-answer tasks, reduces communication overhead, and produces highly transferable optimized prompts. Moreover, it demonstrates greater robustness to data heterogeneity.
Quant-GPT: Money is All You Need
Yuzhe Yang , Kangqi Yu , and Juanquan Peng
2024
A Large Language Model for A-share Market Investment
This paper introduces Quant-GPT, a novel multi-agent optimized for Ashare market investment decisions. Leveraging a fine-tuning combination of distilled sentiment analysis from ChatGPT and real-world market data, the prediction agent of Quant-GPT addresses the challenges of model collapse and weak causality between sentiment and expected returns. Our methodology integrates a Retrieval-Augmented Generation (RAG) agent and summary agent, enabling the model to access relevant news articles and corporate announcements summary with concise investment information to enhance investment decision-making. The inclusion of diverse datasets and RAG significantly improves the model’s ability to forecast market trends and returns accurately. Experimental results demonstrate Quant-GPT’s superior performance over existing open-source LLMs in terms of annualized return, maximum draw-down, and Sharpe ratio. These findings underscore the potential of advanced language models in financial applications, providing a robust framework for integrating natural language understanding with quantitative investment strategies. The code is available on GitHub: https://github.com/TobyYang7/Quant-GPT
LLaVA-Qwen2: Enhanced with Qwen2 Base Model
Yuzhe Yang
2024
An extension of LLaVA integrating the Qwen2 model for enhanced visual instruction tuning.
LLaVA-Qwen2 enhances the LLaVA project by incorporating the Qwen2 base model, aiming to bring GPT-4 level capabilities to visual instruction tuning. This repository provides a custom implementation that leverages the advanced features of Qwen2 for improved performance in large language and vision models. The project includes datasets for pretraining and finetuning, evaluation scripts, and a user-friendly interface. The result is a robust system designed for sophisticated multimodal tasks in various domains, particularly focused on financial applications with the FinVis dataset. Detailed instructions for installation, usage, and model evaluation are provided.
Travel Insurance Recommendation AI System Based on Flight Delay Predictions and Customer Sentiment
Yuzhe Yang , Haoqi Zhang , Zhidong Peng , Yilin Guo , and Tianji Zhou
2024
Predicting Purchase Intentions for Dynamic Insurance Pricing
In this project, we designed an AI system to identify potential travel insurance intentions of customers. Our designed large language model (LLM), named Insurance-GPT, is capable of analyzing in real-time during interactions with users and it utilizes deep learning model to accurately predict flight delay. This provides a good user experience, as well as provides a reference for pricing strategies to insurance companies. The Insurance-GPT can be downloaded at https://modelscope.cn/models/TobyYang7/ InsuranceGPT. Additionally, the complete source code for this project is available on GitHub at https://github.com/TobyYang7/ Travel-Insurance-Recommendation-AI-System.
Flight Information System
Yuzhe Yang , Zitong Wang , Baoyin Zhang , Haoqi Zhang , Jianzhen Chen , and Zhidong Peng
2024
A project focused on enhancing aviation sector data management through a relational database system, integrated with LLM for optimized query generation and user-friendly web interface.
The Flight Information System project aims to revolutionize data management in the aviation sector by developing a sophisticated relational database system. This system, grounded in an Entity-Relationship (E-R) model, is designed to streamline airline operations, including passenger bookings and flight logistics, ensuring data integrity and operational efficiency. By integrating Large Language Models (LLM), the project enhances the database architecture and query generation process, facilitating more intuitive interactions. The outcome is a functional, user-friendly web interface that replicates the complexities of airline management, offering both administrative and user-level interactions.
2023
Evaluation Model of Light Pollution by Multi-conditional AHP
Yuzhe Yang , Jianzhen Chen , and Zhongbin Chen
2023
Performed GIS data analysis and developed a mathematical model to evaluate light pollution, considering factors such as population data and regional income.
Artificial light, while convenient, poses significant risks, including disruption of circadian rhythms in wildlife and severe health consequences for humans. California’s escalating light pollution problem exemplifies the need for effective solutions. To address this, we developed a light pollution risk assessment model focusing on economic, demographic, and ecological impacts, using indicators such as GDP per capita, population density, and the biological abundance index. The model, weighted by the analytic hierarchy process (AHP), was tested in California’s diverse regions—protected areas, rural, suburban, and urban settings. Our findings suggest that interventions, particularly limiting light sources with specific wavelengths, can significantly reduce light pollution risk, especially in suburban areas, demonstrating a risk reduction of up to 2.63%. These results highlight the importance of targeted strategies in mitigating light pollution effectively.
Kaggle Competition: 1st and Future - Player Contact Detection
Hosted by the National Football League (NFL), this competition aimed to detect player contacts using video and player tracking data to improve player safety.
Game Theory Analysis of SEO Strategies: From Methods to Models
Yuzhe Yang , Xiayu Ni , and RongXin Cao
2023
This project examines SEO strategies through the lens of game theory, developing a model to enhance website visibility and ranking. The work involves both theoretical analysis and practical implementation, offering insights into effective SEO techniques.
This project delves into the application of game theory to Search Engine Optimization (SEO) strategies, focusing on enhancing a website’s importance score through various optimization techniques. The study includes the development and implementation of a customized optimization model, comparative analysis of different SEO methods, and validation through real-world system implementation. The findings demonstrate how specific SEO strategies can effectively improve a website’s visibility and ranking in search engine results.









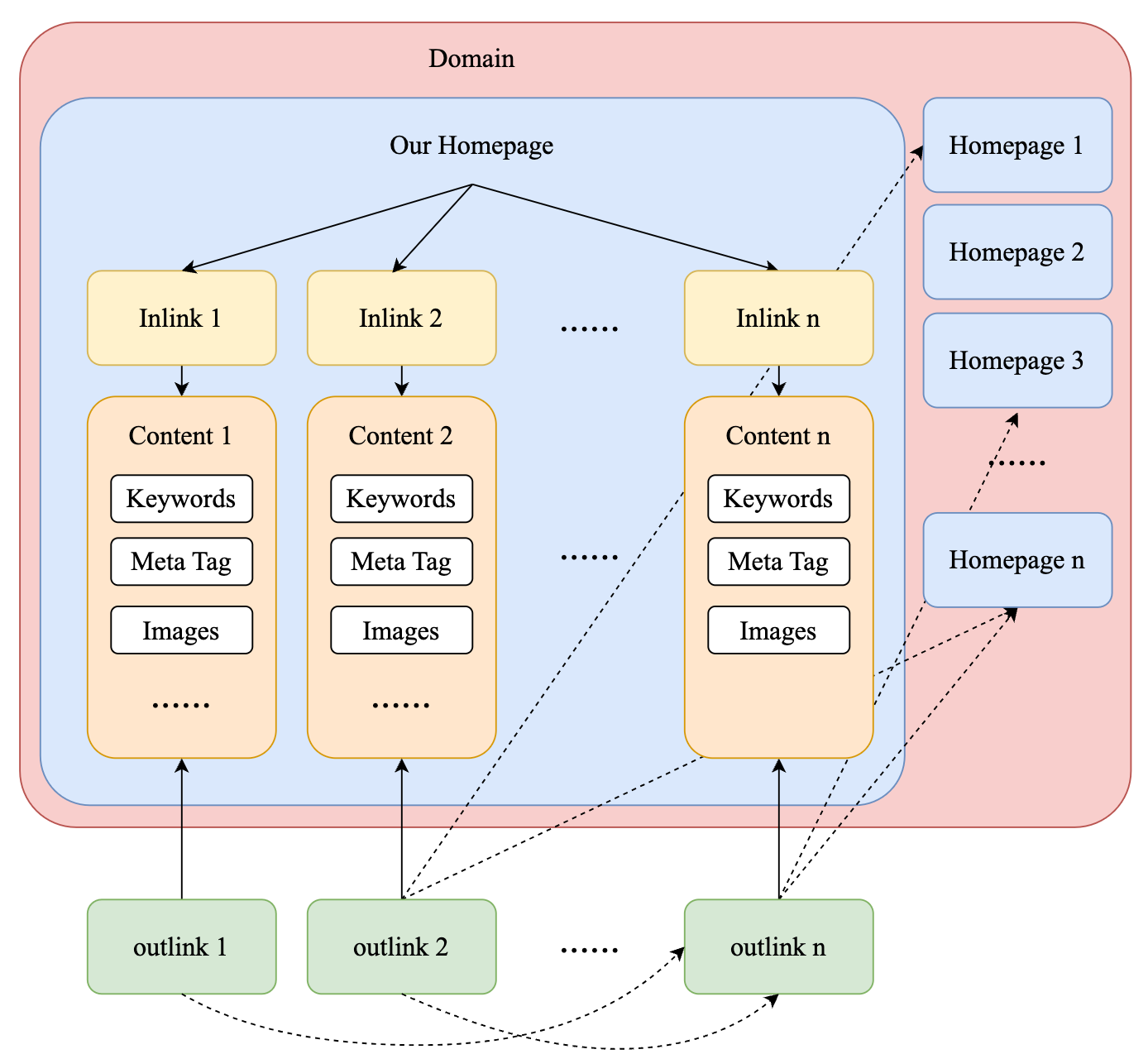 Game Theory Analysis of SEO Strategies: From Methods to Models2023This project examines SEO strategies through the lens of game theory, developing a model to enhance website visibility and ranking. The work involves both theoretical analysis and practical implementation, offering insights into effective SEO techniques.
Game Theory Analysis of SEO Strategies: From Methods to Models2023This project examines SEO strategies through the lens of game theory, developing a model to enhance website visibility and ranking. The work involves both theoretical analysis and practical implementation, offering insights into effective SEO techniques.



